AI Buzzwords: All you need to know! — Part 2
Let us continue upgrading our skillsets! Yay!
Training dataset: It is the subset of the whole dataset used to train the model through learning the hidden patterns in the data. It usually contains the largest corpus of the entire dataset (80% at max) and is used to fit the model. The training dataset should have a diversified set of inputs in such a way that the model is trained in all scenarios and can accurately predict the new/unseen samples in the future.
Validation dataset: Also known as the development set is a separate dataset or a part of the training dataset that is unseen by the model during the training process. Once the model is trained using the training dataset, the validation dataset is used to evaluate the performance of the model during training and fine-tune the hyperparameters. It is very helpful in preventing the model from overfitting.

Test dataset: Once the model is completely trained, the test dataset which is completely hidden from the training and validation process is used to provide an unbiased evaluation of the final model. The training and validation dataset contains labels to check the performance of the model, whereas the test dataset is unlabeled. In general, the test dataset should be well curated such that it contains carefully sampled data across various classes that the model would encounter in a real-world scenario.
Cross-validation: A statistical method or a resampling procedure (in case of limited data) which is used to evaluate the performance of the learning model on different portions of the dataset. In general, cross-validation is carried out by partitioning the dataset into a fixed number of folds, run the analysis on each fold, and average the overall error estimates. Cross-validation techniques can be broadly categorized into (i) Exhaustive methods: Learns and test all possible ways of splitting the dataset into training and validation datasets. E.g., Leave one out and Leave p out, and (ii) Non-exhaustive methods: Do not compute for all possible combinations of the original dataset. E.g., Holdout, K-Fold, Stratified K-Fold, and Monte Carlo CV.
Bias: Bias is the simple assumptions that the model makes about the data to predict new data. Bias or error due to bias is the difference between the actual and predicted values. A high bias model fails to capture/learn the patterns in the training data and thereby does not perform well on the test/unseen data. High bias models provide high training errors and similar test errors.
Low bias models (non-linear models): k nearest neighbor, SVM, and decision trees
High bias models (linear models): linear regression and logistic regression
Try to reduce the high bias through
· Use a more complex model
· Increase input features
· Decrease the regularization term
Variance: ‘model’s sensitivity to fluctuations in the data’ — amount of variation in the prediction with different training datasets. Variance or error due to variance measures how scattered are the predicted values from the actual values due to different training datasets. A model with high variance learns a lot and performs well with the training dataset but produces high error rates on the test dataset. High variance models provide low training error and high test error.
Low variance models (linear models): Linear regression and logistic regression
High variance models (non-linear models): k nearest neighbor, SVM, and decision trees
Try to reduce high variance through:
· Use a less complex model
· Decrease the input features
· Increase the training data and regularization term
Bias-variance trade-off: A simple model with few parameters results in high bias and low variance, whereas a model with more parameters gives out low bias and high variance. Moreover, to increase the accuracy of the prediction, we need to have a low bias and low variance model which is infeasible as decreasing the bias and variance will increase the variance and bias, respectively. So, we always need to have a perfect balance between bias and variance with optimal model complexity is called bias-variance tradeoff.

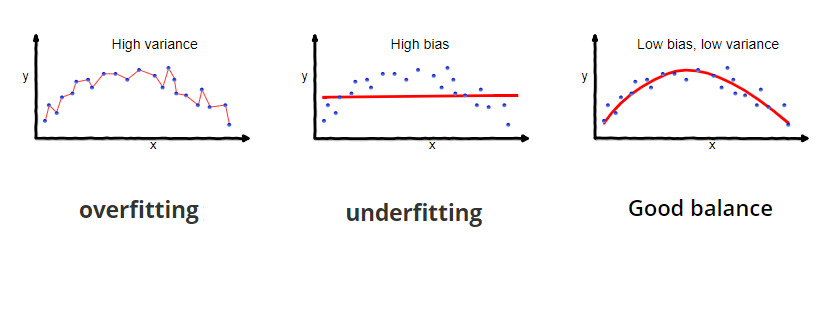
Overfitting: Occurs when the model learns the underlying patterns in the training data completely along with the noise i.e., performs well on the training data but provides poor performance with the test data. It is due to low bias and high variance. Example: Decision trees
Reasons:
- Unclean and insufficient training data (noise or outliers)
- High variance and low bias
- High training time for complex network architectures
- Incorrect tuning of hyperparameters results in over-observing data thereby memorizing features
Solution:
- Increase training data
- Reduce model complexity
- Cross validation
- Early stopping during the training phase
- Ridge and lasso regularization
- Dropout for neural networks
- Adopt ensemble techniques, feature selection, and data augmentation
Underfitting: Occurs when the model has not learned the underlying patterns in the training data and does not generalize well with the test data, i.e., poor performance on the training data and test data.
It is due to high bias and low variance. Example: Linear and logistic regression
Reasons:
- Unclean and insufficient training data (noise or outliers)
- High bias and low variance
- Simple model
- Incorrect hyperparameter tuning results in under-observing features
Solution:
- Increase the number of features, model complexity, and training duration
- Remove noise

Balanced model: A balance model or ‘good-fit’ model achieves a perfect balance between bias and variance and identifies an optimal model between overfitting and underfitting. To achieve a good fit model, stop the training at the point where error tends to increase. Use validation dataset and resampling techniques to achieve ‘good-fit’ model.

Regularization: It is a technique used to reduce the errors by fitting a function appropriately to the training dataset thereby reducing overfitting. It maintains the features in the model by reducing the magnitude of the features and therefore maintains the accuracy and generalization of the model. There are two main regularization techniques (i) L1 or Lasso: adds ‘absolute value of magnitude’ of coefficient as penalty term to the cost function; shrinks the slope to 0; helps in feature selection and (ii) L2 or Ridge: adds ‘squared magnitude’ of coefficient as penalty term to the cost function; shrinks the slope near to 0; includes all features in the model.
Early stopping: A simple and effective regularization technique to prevent overfitting wherein the model is trained using the training dataset and the point at which the training should stop is determined from the validation dataset. The training and validation error steadily decreases until a certain point where the validation error starts to increase. Beyond this point is when the learning model starts to overfit the training data which causes the training error to decrease while the validation error increases. So, we stop training as soon as the validation error reaches a minimum and this strategy of stopping early based on validation set performance is known as early stopping. Moreover, early stopping prevents overfitting and consumes a lesser number of epochs to train.

Keep supporting through clapping 👏 which motivates me to explore and write more. Let's meet in the final part of AI buzzwords soon.

{kind=link}