AI Buzzwords: All you need to know! — Part 3
Hurray! We have reached the completion of the series on simple explanations of AI Buzzwords. Happy Learning!
Gradient descent: An optimization algorithm to train machine learning and deep learning models. It is based on a convex function and it tweaks the parameters of the learning model iteratively to minimize the given function to its local minima i.e., minimize the function by slowly moving in the direction of the steepest descent (negative of the gradient). For example, gradient descent is used to update weights in neural networks and regression coefficients in linear regression. Three types of gradient descent are
- Batch gradient descent: Update parameters based on the whole dataset. Computationally expensive and not preferred for the large training dataset.
- Stochastic gradient descent: Update parameters based on one instance of training data at every step. Not preferred for large training datasets due to additional overhead and a large number of iterations.
- Mini-batch gradient descent: Update parameters based on mini-batch from the whole dataset at every step. Works well for larger training datasets with less number of iterations
“A gradient measures how much the output of a function changes if you change the inputs a little bit.” — Lex Fridman (MIT)
Local minima/maxima: A point in the curve that is minimum/maximum when compared to its preceding and succeeding points. A curve can have multiple local minima/maxima.

Global minima/maxima: A point in the curve that is minimum/maximum when compared to all points in the curve. There will be only one global minima/maxima.
Hyperparameter: In ML/DL, a learning model is represented by the parameters. Hyperparameters are defined as the parameters that are explicitly defined by the users to control the learning process and determine the values of the model parameters that the learning algorithm will use to learn the mapping between the independent and dependent features. The value of the hyperparameters is set before model training and therefore remains unchanged during the training process. A cluster centroid in clustering is the model parameter and k in kNN is the hyperparameter.
Model tuning: The process of maximizing the model’s performance without overfitting or high variance which is generally accomplished by selecting appropriate hyperparameters. Get the best hyperparameters by evaluating the model for each hyperparameter setting and selecting the hyperparameter that gives the best model. Grid search, random search, Bayesian optimization, and Hyperopt are the most widely used methods for the selection of appropriate hyperparameters.
Feature selection: Selecting a subset of features from the original features to reduce model complexity and generalization error due to irrelevant features and enhance the computational efficiency of the model. L1 regularization, feature importance techniques, and greedy search algorithms are a few important feature selection techniques. Moreover, feature selection techniques can be classified based on the,
1. Training data — supervised, unsupervised and semi-supervised
2. Relationship with the learning models — filter, wrapper, and embedded
3. Evaluation criteria — correlation, consistency, Euclidean distance, dependency, and information measure.
4. Output type — feature rank and subset selection methods
Feature selection is used when the requirement is to maintain the original features and model explainability.

Feature extraction: Derives information from the original feature set to create a new feature subspace. Reduce features through compressing data and maintaining most of the relevant information to reduce generalization error, model complexity, overfitting and enhance the computational efficiency. Principal component analysis, linear discriminant analysis, and kernel principal component analysis are a few feature extraction techniques. It helps to improve the performance of the models that do not support regularization.
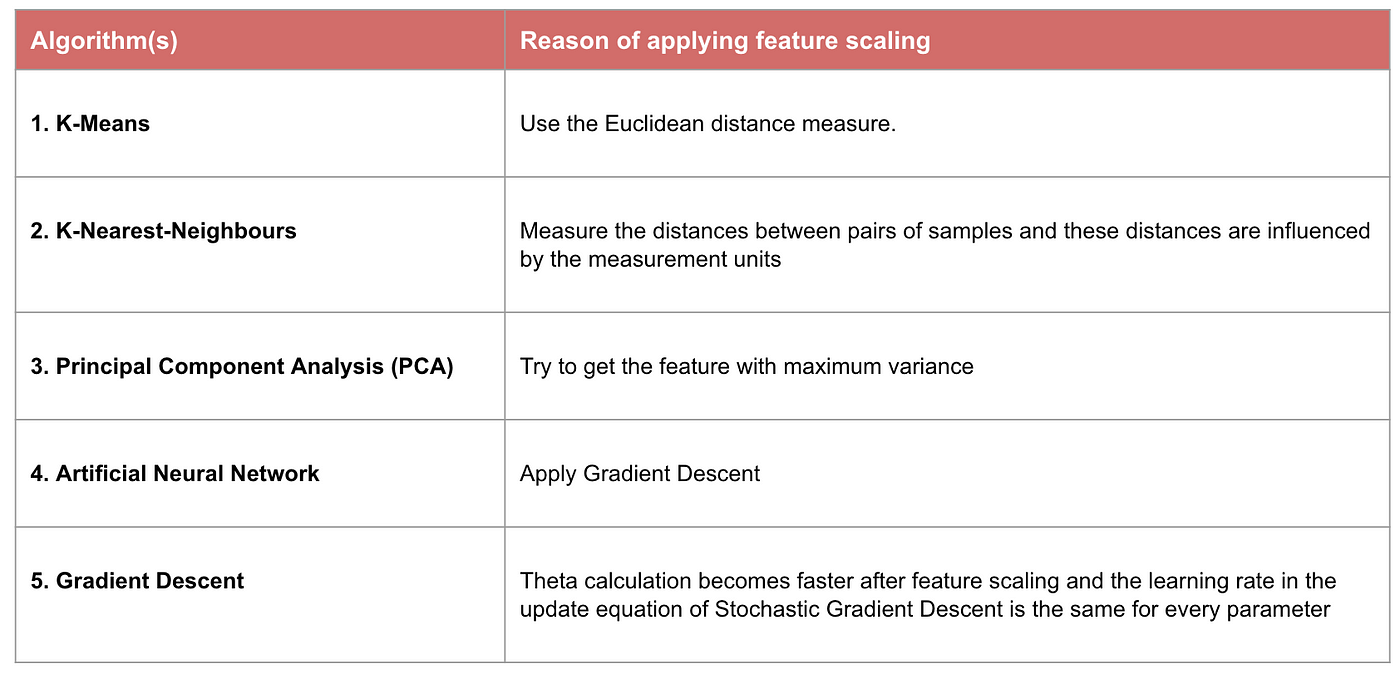
Feature scaling: A crucial data preprocessing step used to normalize the range of the independent variables. Feature scaling is essential for the learning algorithms that compute the distance between the data (e.g., kNN, k-means, gradient descent, and principal component analysis). Learning algorithms that rely on rules do not require feature scaling (e.g., tree-based algorithms, Naive Bayes, and linear discriminant analysis).

Normalization or ’min-max’ scaling: A feature scaling method that rescales the feature values in the range of [0,1] or [-1,1], i.e., makes data homogeneous across records and fields. It is required when the data distribution is unknown and when the learning algorithm does not make assumptions about the data distribution (e.g., ANN). Normalization is highly affected by outliers.

Standardization or ’Z-score’ normalization: A feature scaling method which rescales the data to have a mean of 0 and standard deviation of 1, i.e., placing dissimilar features on the same scale, especially for multivariate analysis. It is required when data follows a Gaussian distribution (bell curve) and when the learning algorithms make assumptions about the data distribution (e.g., logistic regression, linear discriminant analysis). Standardization is slightly affected by outliers.
Backpropagation: ‘backpropagation of errors’ is the most fundamental building block of neural networks. After each forward pass in the neural network, a backward pass is performed by backpropagation while adjusting the weights and bias of the network. The main motive of backpropagation is to minimize the cost function, i.e., minimize the difference between the actual and desired output by adjusting weights and biases. The level of adjustment is determined by the gradients of the cost function with respect to the parameters. The gradient tells you how much the parameter should change in a positive or negative direction to minimize the cost. The gradients are computed using the chain rule of differentiation.
Vanishing gradient problem: A situation encountered during training neural networks where the gradients used to update the weights (output to input layer) shrinks exponentially such that it tends to zero which leaves the weights of the lower layers unchanged. As a result, the gradient never converges to the optimum.

Exploding gradient problem: A situation encountered during training neural networks where the gradients used to update the weights (output to input layer) grows exponentially such that it causes very large weight updates in the lower layers and gradient to diverge.
Vanishing and exploding gradient problems are well handled by the use of ReLU activation function, weight initialization technique (He and Xavier initialization), and gradient clipping.
Weight: A learnable parameter that controls the strength of the connection between two neurons
Bias: A learnable parameter, constant and a additional input to the next layer that always have a value of 1. Bias can be used to make adjustments within the neuron, probably shift the activation function by adding a constant to the input. It always guarantees that even when all inputs are zeros the neurons will be activated.
Learning rate: A hyperparameter that controls the rate at which the algorithm updates/learns the parameter estimates/values. It regulates the weight of the neural network with respect to the loss gradient. The choice of learning rate value impacts how fast the algorithm learns and whether the cost function is minimized or not.

Optimal learning rate — cost function is minimized in a few iterations
Low learning rate — cost function is minimized with more iterations (takes longer time)
High learning rate — cost function saturates at a higher value than the minimum value
Very high learning rate — cost function increases with the iterations

Few learning rate approaches to get optimal learning rate,
Adaptive learning rate — Keeps track of the model’s performance and automatically modifies the learning rate to achieve optimal results. The learning rate is reduced when the gradient value is higher and vice versa.
Decaying learning rate — learning rate drops with the increase in the number of iterations.
Scheduled drop learning rate — learning rate is reduced by a specific proportion at a specific frequency
Cycling learning rate — learning rate changes between the base and maximum rate in a triangular pattern at a constant frequency.
Activation function: A non-linear transformation done on the summed weighted input of a node into an output value that is to fed to the next layer or output layer. Based on the output value, it is decided whether the neuron should be activated or not. The main purpose of the activation function is to add non-linearity to the neural network. A few popular activation functions are binary step (threshold-based), linear activation function (weighted sum of the input), and non-linear activation function (sigmoid, Relu, softmax, etc.).
Few points to remember:
ReLU: Hidden layers
Sigmoid and tanh: do not use in hidden layers due to vanishing gradient problem
Swish: neural networks with more than 40 layers
Regression: Linear
Binary classification: Sigmoid/Logistic
Multiclass classification: Softmax
Multilabel classification: Sigmoid
Hidden layers of the convolutional neural network: ReLU
Hidden layers of the recurrent neural network: Tanh and sigmoid
Optimizer: Mathematical functions that are dependent on the learnable parameters of the model, i.e., weights and biases. They help in changing the weights and learning rate of the neural network to minimize the loss function and maximize efficiency. Well-known optimizers are gradient descent, stochastic gradient descent, mini-batch gradient descent, stochastic gradient descent with momentum, adaptive gradient descent, root mean square propagation, AdaDelta, and adaptive moment estimation. For sparse data use Adagrad, AdaDelta, RMSProp, or Adam.
Loss Vs. Cost function: Both measures the difference between the calculated output and actual output. The loss function measures how well the model performs on a single training sample, whereas the cost function measures the same, i.e., the average of loss function on the entire training dataset.
Loss function: absolute loss, square loss, hinge loss, and 0/1 loss.
Regression loss function: square loss, absolute loss, and Huber loss.
Classification loss function: binary cross-entropy, categorical cross entropy, and Hinge loss
Cost function: mean squared error, mean error, mean absolute error, and SVM cost function.
Transfer learning: The knowledge of a well-trained learning model (massive labeled training data) is applied to a different but related problem, i.e., a new task with limited data. Use transfer learning when
· Lack of sufficient labeled training data to train the model from scratch.
· Availability of a pre-trained model on a similar task.
· Task 1 and task 2 have the same input.

With these insights on the basic terminologies of AI, let us catch up in the next blog on classification metrics. Join your hands to clap if you find my contribution helpful. Keep me motivated to explore, learn, and write. Thank you!

{kind=link}
{kind=link}